
An overview research paper on multi-view HEVC (MV-HEVC) prediction structures for light field video compression was presented during the 2019 SPIE optics + photonics international conference in San Diego, CA.
Light field video is a promising technology for delivering the required six-degrees-of-freedom for natural content in virtual reality. Already existing multi-view coding (MVC) and multi-view plus depth (MVD) formats, such as MV-HEVC and 3D-HEVC, are the most conventional light field video coding solutions since they can compress video sequences captured simultaneously from multiple camera angles.
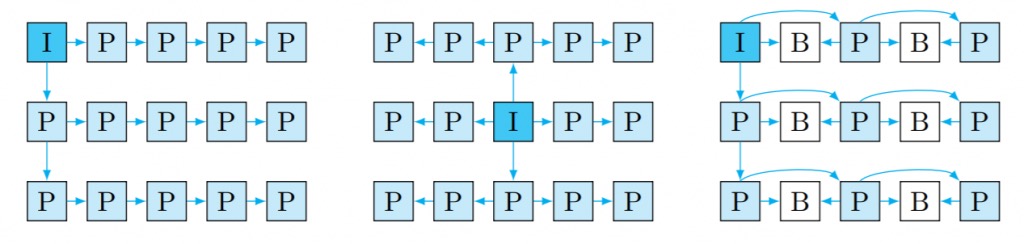
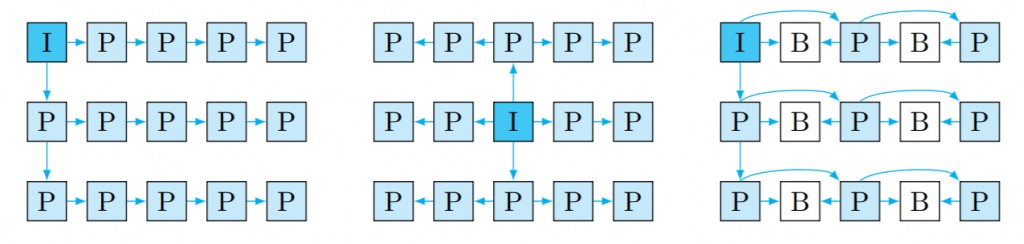
3D-HEVC treats a single view as a video sequence and the other sub-aperture views as gray-scale disparity (depth) maps. On the other hand, MV-HEVC treats each view as a separate video sequence, which allows the use of motion compensated algorithms similar to HEVC. While MV-HEVC and 3D-HEVC provide similar results, MV-HEVC does not require any disparity maps to be readily available, and it has a more straightforward implementation since it only uses syntax elements rather than additional prediction tools for inter-view prediction. However, there are many degrees of freedom in choosing an appropriate structure and it is currently still unknown which one is optimal depending on the application requirements.
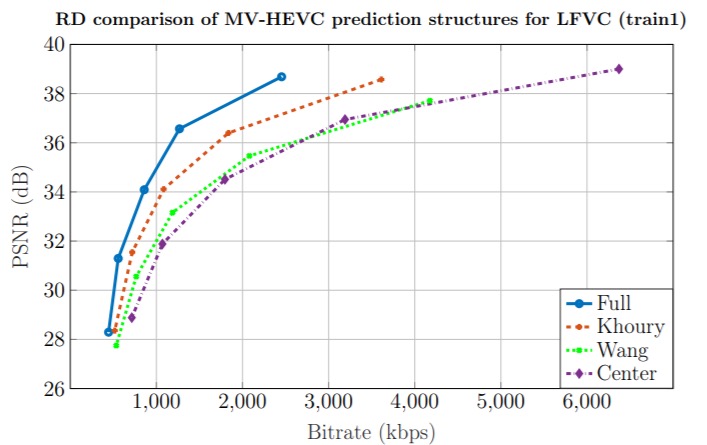
It is interesting to see, what prediction structures for MV-HEVC can offer the best compression efficiency, reconstruction quality and random access capabilities. The findings of the presented paper reveal exactly that. The presented results give an overview of the most optimal solutions developed in the context of this work. The result is a useful benchmark for future development of light field video coding solutions.
The paper can be found here.





{kind=link}