

Our paper, “Steered Mixture-of-Experts for Light Field Images and Video: Representation and Coding”, has been accepted in IEEE Transactions on Multimedia
Key observations
- Introduction of a novel representation method for any-dimensional image data embedded in a strong Bayesian framework
- Multiple short conference papers have been presented on the subject, but no full paper was yet published. Extra novelties are: coding experiments on light field images, novel light field experiments, including subjective tests and novel experiments on light field video
- Instead of pixels, the smallest image-“atom” is the so-called kernel. A kernel simultaneously defines a multi-dimensional region in the image to represent and defines a function (here: a gradient) to use as the representation.
- The model allows for superior coding performance in low- to mid-level bitrates especially when the dimensionality increases, for example in 5-D light field video.
- Nevertheless, the method is mainly interesting for the functionality that it provides, i.e. functionality that will be required for virtual reality applications based on camera-captured data:
- Full zero-delay random access
- Light-weight pixel-parallel view reconstruction
- Intrinsic view interpolation and super-resolution
Abstract
Research in light field (LF) processing has heavily increased over the last decade. This is largely driven by the desire to achieve the same level of immersion and navigational freedom for camera-captured scenes as it is currently available for CGI content. Standardization organizations such as MPEG and JPEG continue to follow conventional coding paradigms in which viewpoints are discretely represented on 2-D regular grids. These grids are then further decorrelated through hybrid DPCM/transform techniques. However, we argue these 2-D regular grids are less suited for high-dimensional data, such as light fields.
 Example of a SMoE model for a grayscale 2-D image. Kernels operate in the joint coordinate and color space (d). Each kernel defines a region of the image to represent and simultaneously defines a grayscale gradient. Note how the model creates a continuous representation from the discrete pixel data.
Example of a SMoE model for a grayscale 2-D image. Kernels operate in the joint coordinate and color space (d). Each kernel defines a region of the image to represent and simultaneously defines a grayscale gradient. Note how the model creates a continuous representation from the discrete pixel data.
In the paper, we propose a novel coding framework for higher-dimensional image modalities, called Steered Mixture-of-Experts (SMoE). Coherent areas in the higher-dimensional space are represented by single higher-dimensional entities, called kernels. These kernels hold spatially localized information about light rays at any angle arriving at a certain region. The global model consists thus of a set of kernels which define a continuous approximation of the underlying plenoptic function. This paper introduces the theory of SMoE and illustrate its application for 2-D images, 4-D LF images, and 5-D LF video. We also propose an efficient coding strategy to convert the model parameters into a bitstream.
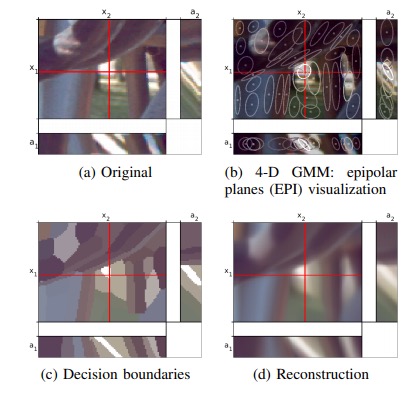 Example of a SMoE model, reconstruction and segmentation of a light field. Notice how single kernels have a spread along all coordinate dimensions, i.e. in the 4-D space. For light field video, the time dimension can be easily added on as SMoE is scalable in dimensionality, a very unique feature.
Example of a SMoE model, reconstruction and segmentation of a light field. Notice how single kernels have a spread along all coordinate dimensions, i.e. in the 4-D space. For light field video, the time dimension can be easily added on as SMoE is scalable in dimensionality, a very unique feature.
Even without provisions for high-frequency information, the proposed method performs comparable to the state of the art for low-to-mid range bitrates with respect to subjective visual quality of 4-D LF images. In case of 5-D LF video, we observe superior decorrelation and coding performance with coding gains of a factor of 4x in bitrate for the same quality.
At least equally important is the fact that our method inherently has desired functionality for light field rendering which is lacking in other state-of-the-art techniques: (1) full zero-delay random access, (2) light-weight pixel-parallel view reconstruction, and (3) intrinsic view interpolation and super-resolution.





{kind=link}